[3분 알고리즘] 랜덤 포레스트

![[3분 알고리즘] 랜덤 포레스트](/content/images/size/w2000/2023/03/075b67b8e7397.png)
지난 글에서 머신러닝 알고리즘 가운데 가장 이해하기 쉽고 의사결정과정이 명확한 의사결정나무 알고리즘에 대해 알아보았다. 다만 의사결정나무는 분기를 어디까지 할 지 파라미터들을 설정하지 않으면 과적합 문제가 발생하기 쉽다는 게 가장 큰 단점이였다.
의사결정나무를 기반으로 한 알고리즘이 많은데 캐글 같은 머신러닝 대회에서는 랜덤 포레스트나 XGBoost처럼 의사결정나무를 기반으로 한 알고리즘의 성능이 좋은 경우가 많다. 이번 글에서는 의사결정나무 알고리즘을 활용한 알고리즘 가운데 하나인 랜덤 포레스트에 대해 알아보도록 하자.
의사결정나무 알고리즘의 형제들
여러가지 알고리즘들을 종합해서 결과는 내는 모델링 방식을 앙상블(Ensemble)이라고 하는데 대표적인 앙상블 기법으로는 서로 다른 알고리즘을 사용해 예측한 결과를 다수결이나 평균으로 결정하는 보팅(Voting)이 있다. 반면, 같은 알고리즘을 사용하되 데이터를 무작위로 추출해 다양한 서브 데이터셋을 생성하고 이들을 병렬적으로 학습한 결과를 다수결이나 평균으로 결정하는 것을 배깅(Bagging) 이라고 한다. 또한, 역시 같은 알고리즘을 사용하면서 앞서 학습한 결과를 가지고 다음 학습기가 순차적으로 학습하면서 오차를 줄여나가는 부스팅(Boosting) 방식도 있다.
랜덤 포레스트는 의사결정나무를 배깅 방식으로 만든 알고리즘으로, 부트스트랩을 통해 다양한 서브 데이터셋을 생성하고 여러 개의 의사결정나무가 각각의 데이터셋을 학습하고 결과를 취합 함으로써 단일 의사결정나무가 가질 수 있는 과적합 문제를 해결할 수 있는 알고리즘이다. 샘플링을 통해 다양한 데이터셋을 학습함으로써 그 과정에서 분산이 줄어들고 다양한 상황에서 안정적인 결과를 도출하길 기대한다고 해야할까?
그라디언트 부스팅(Gradient Boosting) 알고리즘은 의사결정나무를 부스팅 방식으로 적용한 알고리즘으로 이 다음 글에서 다룰 예정이다. XGboost(Extreme Gradient Boosting)는 그 이름에서도 알 수 있듯 그라디언트 부스팅의 정확도와 속도를 더 개선한 모델이라고 생각하면 된다.
[의사결정나무 알고리즘 형제들]

랜덤포레스트의 작동방식
그렇다면 랜덤 포레스트 알고리즘의 구체적인 작동방식에 대해 좀 더 알아보도록 하자.
랜덤 포레스트는 모 데이터에서 n개 샘플 데이터를 중복을 허용해 무작위로 추출, 여러 개의 의사 결정나무 학습기에서 동시에 학습이 이뤄진다. 의사결정나무가 노드를 분할할 때 사용자가 제공한 모든 특성(features)을 활용하는 데 비해 랜덤 포레스트는 전체 특성의 제곱근 (Square Root) 수 만큼 특성을 무작위로 골라 계산한다.
각 분기는 앞서 의사결정나무와 마찬가지로 분류의 경우 지니계수 혹은 엔트로피가 가장 낮아지는 방향으로, 회귀의 경우 MSE가 가장 낮아지는 최적의 분기점을 찾아 분기해 나가게 된다.
사이킷런의 랜덤 포레스트 알고리즘의 디폴트 값을 살펴보면 학습기(n_estimators)는 100개가 생성되도록 되어 있고, 기본적으로 부트스트랩을 활용해 훈련 데이터셋의 개수(max_samples) 만큼 데이터를 샘플링해 학습을 하게 된다. 활용하는 피처 개수(max_features) 역시 제곱근이 디폴트 값이다.
[사이킷런의 랜덤포레스트 알고리즘]
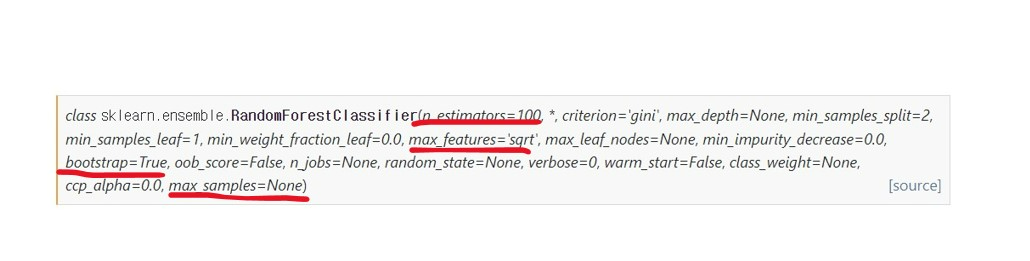
학습이 완료되면 분류의 경우 최종 분기된 leaf node의 확률값을 평균함으로써 예측을 수행하고, 회귀의 경우 각 학습기의 결과를 평균한 값을 예측값으로 한다. 의사결정나무에서 회귀의 경우 데이터의 예측값은 데이터가 속한 leaf node의 평균값이 되는데 랜덤 포레스트의 경우 그렇다면 평균의 평균이 되는 셈이다.
사이킷런 의사결정나무로 모델링하기
지난 번과 마찬가지로 키&몸무게 특성을 가지고 클래스 0, 1, 2로 분류하는 데이터셋을 가지고 랜덤 포레스트 알고리즘을 연습해 보자.
랜덤 포레스트의 하이퍼 파라미터 역시 기본적으로 의사결정나무에서 물려받은 max_depth나 min_sample_leaf 등을 설정하지 않으면 과적합되기 쉽다. 그 외 랜덤 포레스트만 가지는 하이퍼 파라미터로는 앞서 말한 학습기 수(n_estimators), 샘플링할 데이터 개수(max_samples) 등이 있고, 역시 데이터셋의 특징이나 목표에 따라 최적의 하이퍼 파라미터를 다양하게 테스트해 볼 필요가 있다.
[사이킷런의 랜덤포레스트로 모델링하기]
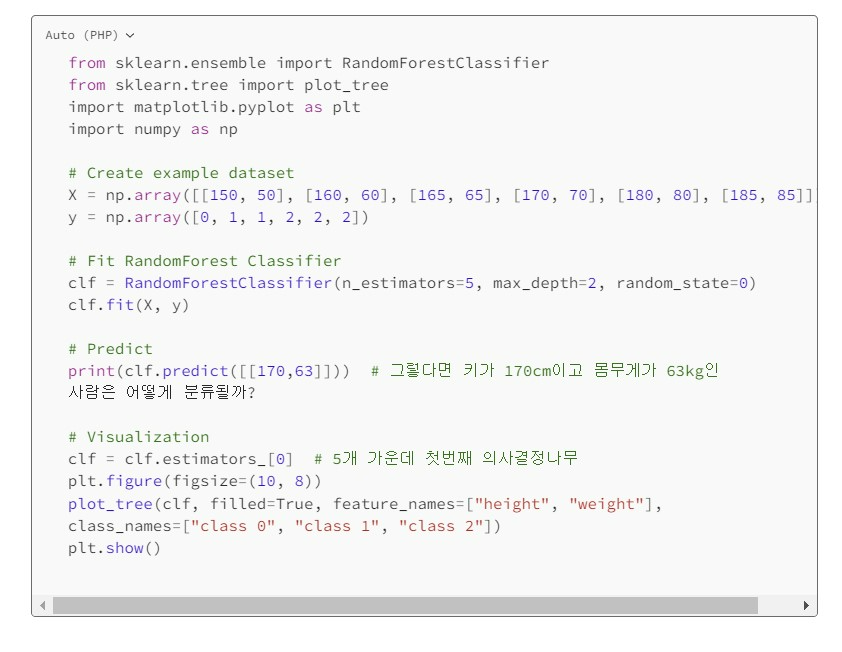

역시 모델링한 결과를 시각화 할 수 있는데, 랜덤 포레스트의 여러 개 의사결정나무 가운데 하나를 골라 시각화할 수 있다. 위의 예시에서는 5개의 가운데 첫 번째 의사결정나무(estimators_[0])의 결과를 시각화 해보았다.
다음 글에서는 역시 의사결정나무 알고리즘을 활용하지만 이전 학습기의 학습 결과를 학습해 계속해서 강해지는 그라디언트 부스팅에 대해 알아보도록 하자.
| ||
마테크와 마케팅 데이터 분석에 대해 이야기 합니다. |

*슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.