[3분 알고리즘] 의사결정나무 알아보기

![[3분 알고리즘] 의사결정나무 알아보기](/content/images/size/w2000/2023/03/fb5143a52e7c5.png)
머신러닝을 적용할 때 가장 많이 사용하는 알고리즘 중에 하나로 의사결정나무(Decision Tree)가 있다. 많은 머신러닝 알고리즘들이 각자의 가설함수와 손실함수, 그리고 최적화 함수를 가지고 최적의 가중치를 찾는 과정인데 비해 의사결정나무는 우리가 흔히 알고 있는 스무고개 놀이와 비슷하다.
최대 20개 질문에 대해 예 또는 아니오로 대답하는 과정에서 답을 알아맞추는 놀이 말이다. 예를 들어 어떤 사람의 MBTI를 맞춘다고 할 때 ‘주기적으로 새 친구를 만든다’, ‘계획을 세우기 보다 즉흥적으로 움직이는 편이다’ 등 외향/내향, 감각/직관, 사고/감정, 판단/인식 등 MBTI를 판단할 수 있는 질문들을 함으로써 그 사람의 MBTI를 예측해 보는 것이다.
물론 실제 머신러닝 과정에서는 딱 20개의 질문만 할 수 있는 것도 아니고 한 사람이 아니라 수십 만 혹은 수백 만명의 데이터를 분류하게 된다. 공통적으로는 어떤 질문을 하는 지가 예측 정확도를 높이는데 중요할 것이라는 것을 알 수 있다.
의사결정나무 알고리즘은 사용자가 제공한 질문, 즉 데이터 특성들(features)를 사용해 데이터를 분류해 나가는데, 그렇다면 주어진 특성들을 이용해 어떻게 데이터를 분류해 나가는 지 의사결정나무의 작동 방식을 구체적으로 한 번 알아보도록 하자.
분류일 때 의사결정나무
의사결정나무에는 ID3, CART 등 여러가지 알고리즘이 있지만 불순도로 지니계수(Gini index)를 사용하고 분류 & 회귀 문제 모두에 사용할 수 있는 CART(Classification and Regression Tree) 방식을 중심으로 설명해보자.
지니계수는 불순도를 말하는 것으로 예를 들어 데이터넷에서 클래스 0과 1의 비중이 비슷하다면 불순도가 높은 것이다. 특히, 클래스 0과 1의 개수가 똑같다=정보 차이가 존재하지 않는다는 의미로 어느 클래스에 속할 지 예측할 수 없는 불확실성이 아주 큰 상태이다.
의사결정나무는 불순도, 즉 지니계수가 낮아지는 방향으로 계속 분기를 하는데 분류의 경우 최종적으로는 높은 예측 정확도를 목표로 할 수 있을 것이다.
사람의 키와 몸무게를 특성으로 하고 클래스 0, 1, 2로 분류하는 데이터셋이 있다고 하자. 의사결정나무는 각 피처의 모든 데이터를 분기점(split point)으로 고려해 두 개의 하위 그룹으로 나눴을 때 가장 지니계수가 낮아지는 피처와 그 값을 분기점으로 선택하게 된다.
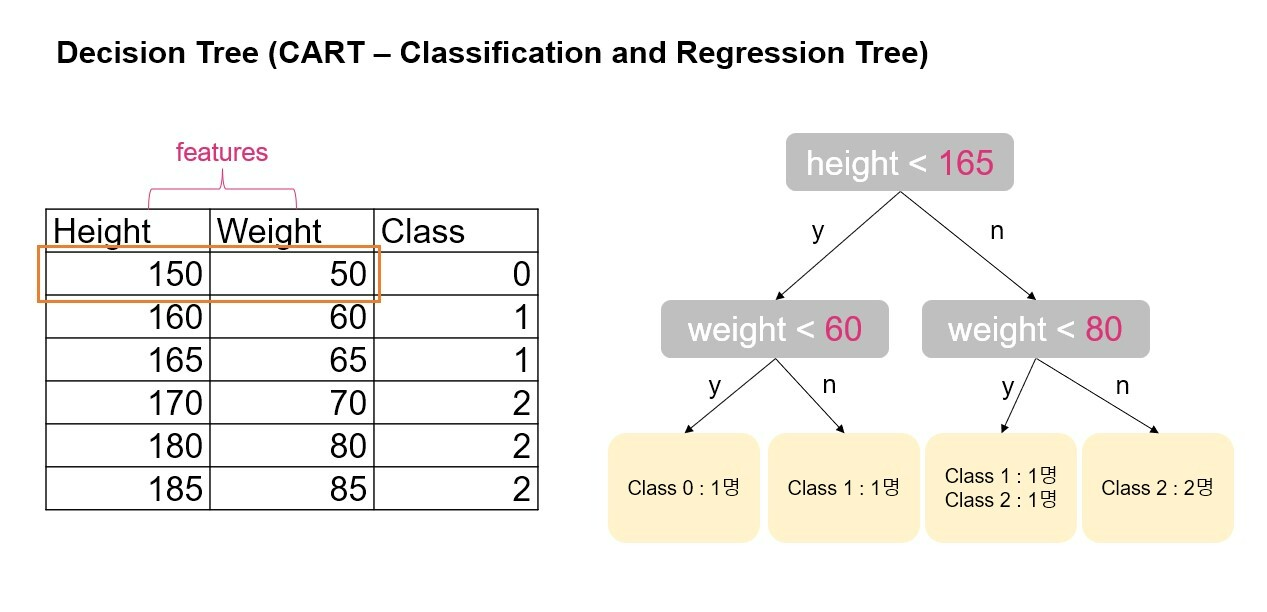
Decision Tree 예시
예를 들어 height<150와 같이 키의 모든 데이터 값인 150, 160, 165, 170, 180, 185를 기준으로 데이터셋을 두 그룹으로 분류했을 때 각각의 경우 지니계수를 계산하고, 마찬가지로 다른 피처인 몸무게의 모든 데이터 포인트를 기준으로 분류할 경우 지니계수를 계산, 각 피처와 데이터 조합을 통틀어 지니계수가 가장 낮아지는 값을 첫 번째 분기점으로 선택한다.
첫 번째 분기 포인트로 height<165가 선택되었다면 분기된 두 그룹의 각각의 데이터셋에서 다시 고려할 수 있는 모든 피처와 값들을 가지고 지니계수를 계산해 가장 지니계수가 낮은 경우를 두 번째 분기점으로 계속 분기를 해 나가게 된다.
그렇다면 언제까지 분기를 해 나가게 될까? 바로 지니계수가 0이 되거나 분기횟수(max depth), 최종 리프노드 수(max leaf nodes), 최종 리프가 되기 위한 최소 샘플수(min samples leaf) 등 사용자가 지정한 조건에 도달할 때까지이다.
회귀일 때 의사결정나무
실수값을 예측하는 회귀 문제의 경우에도 기본적으로 동일하게 CART 알고리즘이 작동하는데 회귀의 경우 불순도가 아니라 평균제곱오차(MSE)가 낮아지는 방향으로 분기를 하게 된다.
분기가 완료된 후 새로운 데이터에 대한 예측값은 새로운 데이터가 속하게 되는 노드 그룹의 트레이닝 샘플들의 평균값이 된다.
회귀 문제에서 생각해 볼 수 있듯 사용자가 지정한 조건 없이 지니계수가 0이 될 때까지 무제한(?) 으로 나둔다면 최종적으로 생성되는 리프노드는 아주 많고, 아주 작은 실수 구간을 가진 과적합된 모델이 나올 수도 있다. 그래서 이러한 과적합 문제를 막기 위해 앞서 말한 조건들을 지정할 필요가 있다.
사이킷런 라이브러리로 모델링하기
그렇다면, 사이킷런에서 분류를 위한 의사결정나무 알고리즘인 DecisionTreeClassifier를 불러와 간단히 의사결정나무 모델링을 해보자.
앞서 데이터셋을 DecisionTreeClassifier에 넣어서 학습시키고 plot_tree 함수를 사용해 모델링 결과를 시각화해보자. weight > 67.5를 기준으로 분기할 경우 class 2가 완벽히 분류되고, weight <=67.5인 경우를 다시 height <=155를 기준으로 분기하면 클래스 0과 1이 완벽히 분류되는 것을 볼 수 있다.
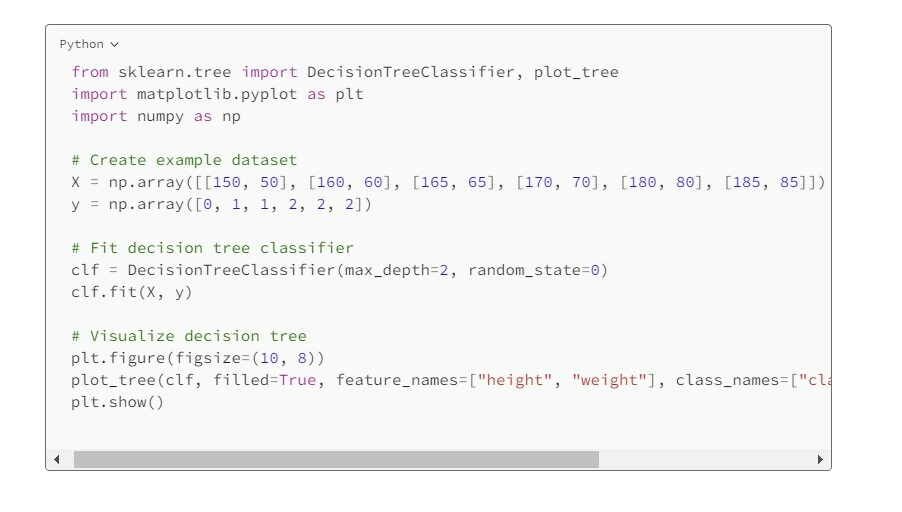
사이킷런의 DecisionTreeClassifier로 모델링하기

사이킷런의 plot_tree 함수를 사용해 결과를 시각화
참고로 사이킷런의 DecisionTreeClassifier는 CART와 조금 달리 각 피처의 데이터 값들을 오름차순으로 정렬한 후 인접한 두 유니크 값들의 중앙값을 후보군(Candidates)으로 지니계수를 계산하기에 67.5나 155와 같은 중앙값들이 기준이 되는 것을 볼 수 있다.
의사결정나무는 데이터가 왜 그렇게 분류되고 예측되는 지 그 의사결정과정을 명확히 알 수 있고 시각화 할 수 있다는 것이 가장 큰 장점일 것이다. 단점은 과적합화될 가능성이 커 하이퍼 파라미터들의 테스팅이 필요하는 것이다. 머신러닝 프로젝트에서 주로 가장 좋은 성능을 내는 알고리즘인 RandomForest, XGBoost, LGBM 등은 모두 의사결정나무에 기반해 그 단점을 보완한 알고리즘들이다. 다음 글에서는 그중에서도 랜덤 포레스트에 대해 먼저 소개할 예정이다.
| ||
마테크와 마케팅 데이터 분석에 대해 이야기 합니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.